Songhay Publications and the Concept of the Index
What you are reading now is a Songhay Publication, this Blog. A Songhay Publication centers around the Document [GitHub]. Several Document instances can be grouped under one or more Segment [GitHub] instances. Further up the hierarchy, a Segment can group other Segment instances. Here is a diagram of the Segment, the Document (and the Fragment) to confuse almost everyone including me:
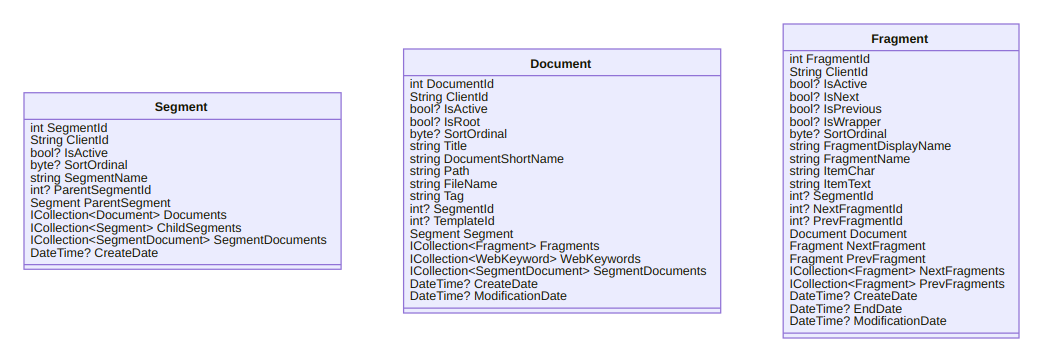
Some of the confusion comes from legacy Entity Framework concerns, specifically the use of ICollection<T> and other association properties. When I simplify my life with small-scale use of static JSON files, we can remove our concern for defining associations. Moreover, my small-scale use of Markdown eliminates the need (almost entirely) for Fragment. After all of this removing and eliminating, at least I can understand why I have the core interfaces, ISegment [GitHub] and IDocument [GitHub], of Songhay Publications:
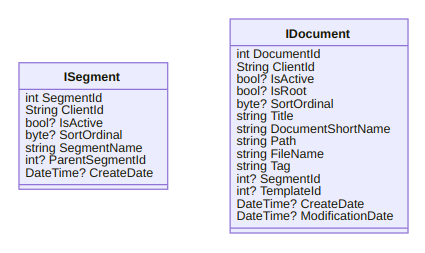
the Web Publication Index
Compiling a collection of ISegment groups into a file renders an Publication Index. Meanwhile, in the real world, there is the confusion between a “table of contents” and an Index. As of this writing in the Songhay studio, we avoid this confusion by defining an Index here and looking forward to defining a Keyword Index (which is a real-world index).
All of this fantastic thinking about the Index comes from my work on rendering a Web Publication Index in HTML. I have been working on the visual design of two kinds of Index layouts:
- the Index
- the Blog Index
Behind the visual design is the information design (too many years of my life was spent here). Both of these visual layouts are driven by a static JSON file this getting closer and closer to shapes of the models in Songhay.Publications. Today, I assume Songhay Index data will eventually look like this:
[
{
"segmentName": "Section 1",
"segments": [
{
"segmentName": "Section 1.1",
"segments": [
{
"segmentName": "Section 1.1.1"
},
{
"segmentName": "Section 1.1.2"
},
{
"segmentName": "Section 1.1.3"
}
]
},
{
"segmentName": "Section 1.2",
"segments": [
{
"segmentName": "Section 1.2.1"
},
{
"segmentName": "Section 1.2.2"
},
{
"segmentName": "Section 1.2.3"
}
]
},
{
"segmentName": "Section 1.3",
"segments": [
{
"segmentName": "Section 1.3.1"
},
{
"segmentName": "Section 1.3.2"
},
{
"segmentName": "Section 1.3.3"
}
]
}
]
},
{
"segmentName": "Section 2",
"segments": [
{
"segmentName": "Section 2.1",
"segments": [
{
"segmentName": "Section 2.1.1"
},
{
"segmentName": "Section 2.1.2"
},
{
"segmentName": "Section 2.1.3"
}
]
},
{
"segmentName": "Section 2.2",
"segments": [
{
"segmentName": "Section 2.2.1"
},
{
"segmentName": "Section 2.2.2"
},
{
"segmentName": "Section 2.2.3"
}
]
}
]
}
]
The JSON above is truncated for prose reading which means that Document data has been left out. For example, Section 2.2 would have documents shaped like this:
{
"segmentName": "Section 2.2",
"segments": [
{
"segmentName": "Section 2.2.1",
"documents": [
{
"title": "Article 2.2.1.1",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
},
{
"title": "Article 2.2.1.2",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
},
{
"title": "Article 2.2.1.3",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
}
]
},
{
"segmentName": "Section 2.2.2",
"documents": [
{
"title": "Article 2.2.2.1",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
},
{
"title": "Article 2.2.2.2",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
}
]
},
{
"segmentName": "Section 2.2.3",
"documents": [
{
"title": "Article 2.2.3.1",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
},
{
"title": "Article 2.2.3.2",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
},
{
"title": "Article 2.2.3.3",
"fileName ": "..",
"modificationDate ": "..",
"path": "..",
"sortOrdinal": "..",
"tag": ".."
}
]
}
]
}
the Songhay Publications Index in Typescript
The JSON above can be used as a guide to define a single Index entry in Typescript:
interface IndexEntry extends Partial<Segment> {
segments?: IndexEntry[];
documents?: Partial<Document>[];
}
I made a little manual test to verify that this interface is working.
distinguishing the search index from the Publication Index
I have opened an issue in the Publications repo because I introduced the Index concept to Songhay Publications to refer to a search Index. My work on a lunr search index at the beginning of this year was and is very exciting but lost sight of the bigger picture: a search Index must be distinguished from the Publication Index being introduced here.
Why can’t this search index be related to the Publication Index? Let us take a look at the lunr search index in use as of this writing:
[
{
"extract": "...",
"clientId": "..",
"inceptDate": "...",
"modificationDate": "...",
"title": "..."
},
{
"extract": "...",
"clientId": "..",
"inceptDate": "...",
"modificationDate": "...",
"title": "..."
},
]
It is clear that what we are looking at is an array of Partial<Document> with this extract property tacked on. (The inceptDate property, by the way, maps to the createDate property on Document; there is an issue out there addressing this weirdness).
Songhay Publications has a method for producing an extract from Document. So it is quite clear that a search index is a very simplified form of our new Publications Index.
Again, in Typescript we can formally and precisely define the SearchIndexEntry:
interface SearchIndexEntry extends Partial<Document> {
string extract;
}
By writing this, I see now that I can replace the LunrIndexEntry I have defined for this Blog Publication with the more generalized SearchIndexEntry.